Configure Autoscaling
EKS Cluster Autoscaler
Cluster autoscaling in EKS is achieved using Cluster Autoscaler. The Kubernetes Cluster Autoscaler automatically adjusts the number of nodes in your cluster based on the resources required and execute the jobs.
Cluster Autoscaler for AWS provides integration with Auto Scaling groups.
Configure the ASG
Lets configure the size of the Auto Scaling group of the newly deployed EKS managed nodegroup.
# we need the ASG name
export ASG_NAME=$(aws eks describe-nodegroup --cluster-name eksworkshop-eksctl --nodegroup-name emrnodegroup --query "nodegroup.resources.autoScalingGroups" --output text)
# increase max capacity up to 6
aws autoscaling \
update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 3 \
--desired-capacity 3 \
--max-size 6
# Check new values
aws autoscaling \
describe-auto-scaling-groups \
--auto-scaling-group-names ${ASG_NAME} \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='eksworkshop-eksctl']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
IAM roles for service accounts
Before deploying cluster autoscaler, refer to IAM roles for service accounts section to add an IAM role to a Kubernetes service account.
Deploy Cluster Autoscaler (CA)
Follow the instructions in section Deploy Cluster Autoscaler for deployment of CA.
kubectl get deployment cluster-autoscaler -n kube-system
Now that we have setup Cluster Autoscale, lets test out a few ways of customizing how Spark jobs run on EMR on EKS. One of the way is to manually change Spark executor config parameters.
For a sample workload, lets use the following code, which creates multiple parallel threads and waits for a few seconds to test out cluster autoscaling.
cat << EOF > threadsleep.py
import sys
from time import sleep
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("threadsleep").getOrCreate()
def sleep_for_x_seconds(x):sleep(x*20)
sc=spark.sparkContext
sc.parallelize(range(1,6), 5).foreach(sleep_for_x_seconds)
spark.stop()
EOF
aws s3 cp threadsleep.py ${s3DemoBucket}
Let’s run the same inbuilt example scripts that calculates the value of pi, but this time lets increase the number of executors to 15 by modifying spark.executor.instances.
#Get required virtual cluster-id and role arn
export VIRTUAL_CLUSTER_ID=$(aws emr-containers list-virtual-clusters --query "virtualClusters[?state=='RUNNING'].id" --output text)
export EMR_ROLE_ARN=$(aws iam get-role --role-name EMRContainers-JobExecutionRole --query Role.Arn --output text)
#start spark job with start-job-run
aws emr-containers start-job-run \
--virtual-cluster-id=$VIRTUAL_CLUSTER_ID \
--name=threadsleep-clusterautoscaler \
--execution-role-arn=$EMR_ROLE_ARN \
--release-label=emr-6.2.0-latest \
--job-driver='{
"sparkSubmitJobDriver": {
"entryPoint": "'${s3DemoBucket}'/threadsleep.py",
"sparkSubmitParameters": "--conf spark.executor.instances=15 --conf spark.executor.memory=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1"
}
}' \
--configuration-overrides='{
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.dynamicAllocation.enabled":"false",
"spark.kubernetes.executor.deleteOnTermination": "true"
}
}
]
}'
You can open up couple of terminals and use watch command to see how cluster autoscales adds additional nodes to schedule the additional executors spark job has requested.
watch kubectl get pods -n spark
watch kubectl get nodes
You can also change CPU and memory of your Spark executors by modifying spark.executor.cores and spark.executor.memory. Learn more about it here.
Let the job run to completion before moving ahead to next section of Dynamic Resource Allocation.
Dynamic Resource Allocation
You can also optimize your jobs by using Dynamic Resource Allocation (DRA) provided by Spark. Its a mechanism to dynamically adjust the resources your application occupies based on the workload. With DRA, the spark driver spawns the initial number of executors and then scales up the number until the specified maximum number of executors is met to process the pending tasks. Idle executors are terminated when there are no pending tasks.
It is particularly useful if you are not familiar of your workload or want to use the flexibility of kubernetes to request resources as necesaary.
Dynamic resource allocation (DRA) is available in Spark 3 (EMR 6.x) without the need for an external shuffle service. Spark on Kubernetes doesn’t support external shuffle service as of Spark 3.1, but DRA can be achieved by enabling shuffle tracking.
To add DRA, we will enable it and define executor behavior in --configuration-overrides section.
#start spark job with start-job-run
aws emr-containers start-job-run \
--virtual-cluster-id=$VIRTUAL_CLUSTER_ID \
--name=threadsleep-dra \
--execution-role-arn=$EMR_ROLE_ARN \
--release-label=emr-6.2.0-latest \
--job-driver='{
"sparkSubmitJobDriver": {
"entryPoint": "'${s3DemoBucket}'/threadsleep.py",
"sparkSubmitParameters": "--conf spark.executor.instances=1 --conf spark.executor.memory=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1"
}
}'\
--configuration-overrides='{
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.dynamicAllocation.enabled":"true",
"spark.dynamicAllocation.shuffleTracking.enabled":"true",
"spark.dynamicAllocation.minExecutors":"1",
"spark.dynamicAllocation.maxExecutors":"10",
"spark.dynamicAllocation.initialExecutors":"1",
"spark.dynamicAllocation.schedulerBacklogTimeout": "1s",
"spark.dynamicAllocation.executorIdleTimeout": "5s"
}
}
]
}'
You have set the spark.executor.instances to 1 and enabled DRA by setting spark.dynamicAllocation.enabled true. For testing purposes, we have kept smaller scale up and scale down timers. Learn more about them here.
You can open up couple of terminals and use watch command to see how DRA scales up and scales down executor instances.
watch kubectl get pods -n spark
As executor instances are scaled up by DRA, kubernetes cluster autoscaler adds nodes to schedule those nodes.
watch kubectl get nodes
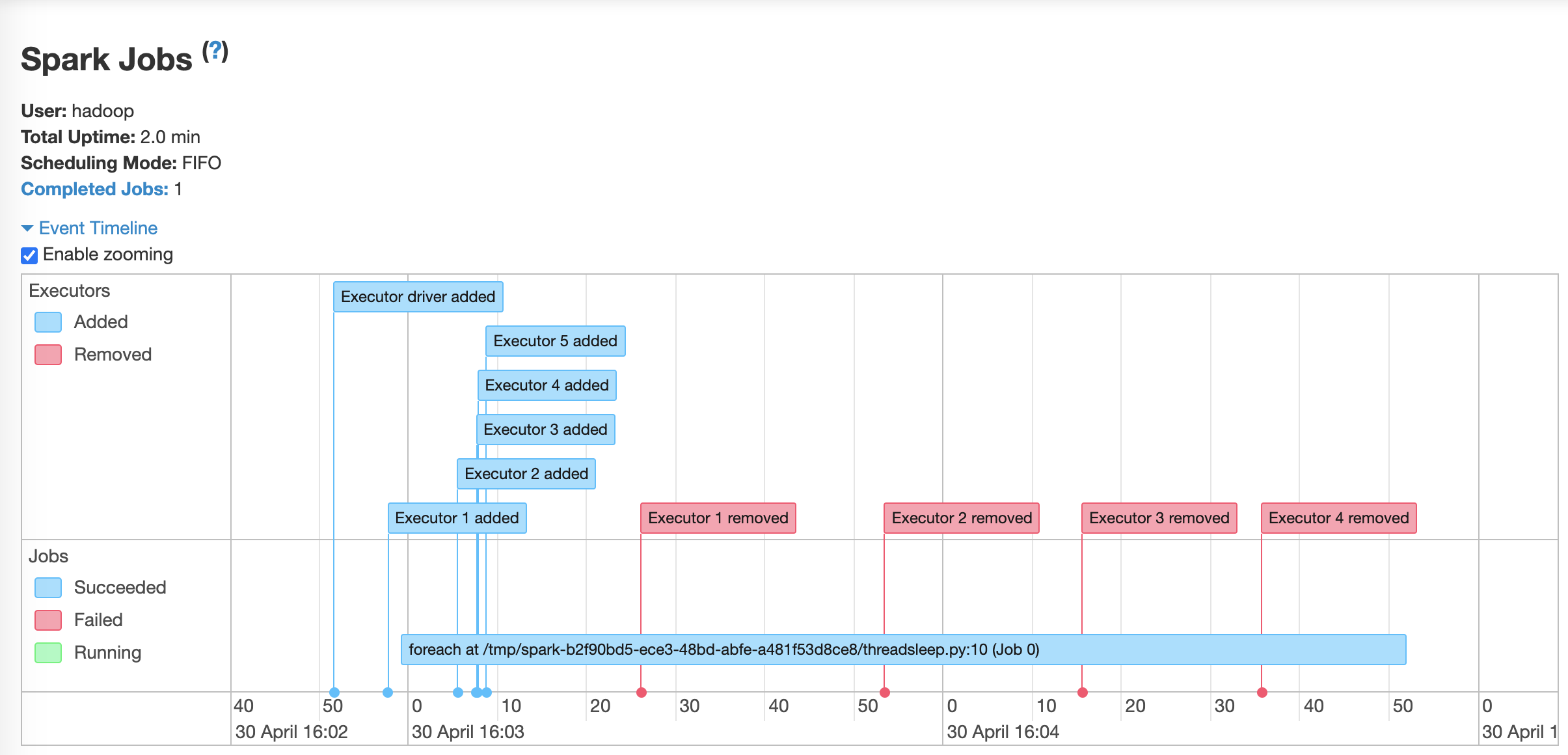
You can also take a look at the spark history server to observe the event timeline for executors - where spark dynamically adds in executors and removes as they are not needed.
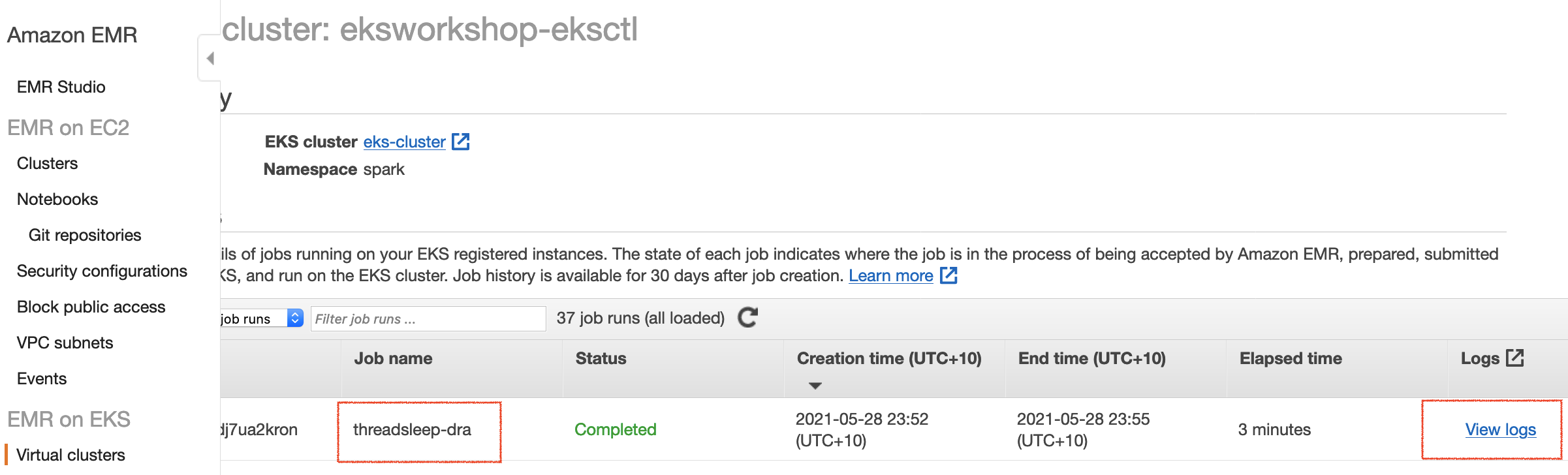
Navigate to the Spark history server on EMR console:
echo -e "Go to the URL:\nhttps://console.aws.amazon.com/elasticmapreduce/home?region="${AWS_REGION}"#virtual-cluster-jobs:"${VIRTUAL_CLUSTER_ID}
Click on View logs:
Check the Event Pipeline: