Using Node Selectors
AWS EKS clusters can span multiple AZs in a VPC. A Spark application whose driver and executor pods are distributed across multiple AZs can incur inter-AZ data transfer costs. To minimize or eliminate inter-AZ data transfer costs, you can configure the application to only run on the nodes within a single AZ. In this example, we use the kubernetes node selector “topology.kubernetes.io/zone” to specify which AZ should the job run on.
You will use spark jobs running on EKS to analyze the New York City Taxi and Limousine Commision (TLC) Trip Record Data . For calendar years 2019 and 2020, you will calculate top-10 pickup locations in New York area based on total amount of distance travelled by the taxi’s. The data is available at Registry of Open Data on AWS at https://registry.opendata.aws/nyc-tlc-trip-records-pds/.
Creating Nodegroup
Amazon EKS managed node groups automate the provisioning and lifecycle management of nodes (Amazon EC2 instances) for Amazon EKS Kubernetes clusters. All managed nodes are provisioned as part of an Amazon EC2 Auto Scaling group that’s managed for you by Amazon EKS. All resources including the instances and Auto Scaling groups run within your AWS account. Each node group run across multiple Availability Zones that you define.
We will now create a managed node group for our example, let’s create a config file (addnodegroup-nytaxi.yaml) with details of a new managed node group.
cat << EOF > addnodegroup-nytaxi.yaml
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eksworkshop-eksctl
region: ${AWS_REGION}
managedNodeGroups:
- name: emr-ny-taxi
minSize: 6
desiredCapacity: 6
maxSize: 6
instanceType: m5.xlarge
ssh:
enableSsm: true
EOF
Create the new EKS managed nodegroup. This node group will have 6 EC2s running across three AZs.
eksctl create nodegroup --config-file=addnodegroup-nytaxi.yaml
Spark Pod Template
Next, you will create a pod template for Spark Executor. Here, we are specifying nodeSelector as eks.amazonaws.com/nodegroup: emr-ny-taxi and topology.kubernetes.io/zone: us-west-2a. This will ensure that spark executors are running in a single AZ (us-west-2 in this example) and are part of nodegroup which we created for analyzing New York taxi dataset.
We chose us-west-2 as this example was ran in Oregon. If you are running in a different region, make sure that the correct zone is selected.
cat > spark_executor_nyc_taxi_template.yml <<EOF
apiVersion: v1
kind: Pod
spec:
volumes:
- name: source-data-volume
emptyDir: {}
- name: metrics-files-volume
emptyDir: {}
nodeSelector:
eks.amazonaws.com/nodegroup: emr-ny-taxi
topology.kubernetes.io/zone: us-west-2a
containers:
- name: spark-kubernetes-executor # This will be interpreted as Spark executor container
EOF
Next, you will create a pod template for Spark Driver. Here, we are specifying nodeSelector as eks.amazonaws.com/nodegroup: emr-ny-taxi and topology.kubernetes.io/zone: us-west-2a. The Spark Driver pods will run in the same AZ as Spark executor pods.
cat > spark_driver_nyc_taxi_template.yml <<EOF
apiVersion: v1
kind: Pod
spec:
volumes:
- name: source-data-volume
emptyDir: {}
- name: metrics-files-volume
emptyDir: {}
nodeSelector:
eks.amazonaws.com/nodegroup: emr-ny-taxi
topology.kubernetes.io/zone: us-west-2a
containers:
- name: spark-kubernetes-driver # This will be interpreted as Spark driver container
EOF
Lets create a nytaxi.py file which will have spark code for analyzing the data set.
cat << EOF > nytaxi.py
import sys
from time import sleep
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.window import Window
spark = SparkSession.builder.appName('uber_nyc_data').getOrCreate()
yellowtripdata_2020 = spark.read.format('csv').option('header', 'true').load('s3://nyc-tlc/trip data/yellow_tripdata_2020*')
yellowtripdata_2020 = yellowtripdata_2020.withColumn('year', F.lit(2020))
yellowtripdata_2019 = spark.read.format('csv').option('header', 'true').load('s3://nyc-tlc/trip data/yellow_tripdata_2019*')
yellowtripdata_2019 = yellowtripdata_2019.withColumn('year', F.lit(2019))
yellowtripdata = yellowtripdata_2020.union(yellowtripdata_2019.select(yellowtripdata_2020.columns))
yellowtripdata = yellowtripdata.withColumn('total_amount', F.col('total_amount').cast('double'))
yellowtripdata = yellowtripdata.withColumn('tip_amount', F.col('tip_amount').cast('double'))
yellowtripdata = yellowtripdata.withColumn('trip_distance', F.col('trip_distance').cast('double'))
greentripdata_2020 = spark.read.format('csv').option('header', 'true').option('inferschema', 'true').load('s3://nyc-tlc/trip data/green_tripdata_2020*')
greentripdata_2020 = greentripdata_2020.withColumn('year', F.lit(2020))
greentripdata_2019 = spark.read.format('csv').option('header', 'true').option('inferschema', 'true').load('s3://nyc-tlc/trip data/green_tripdata_2019*')
greentripdata_2019 = greentripdata_2019.withColumn('year', F.lit(2019))
greentripdata = greentripdata_2020.union(greentripdata_2019.select(greentripdata_2020.columns))
greentripdata = greentripdata.withColumn('total_amount', F.col('total_amount').cast('double'))
greentripdata = greentripdata.withColumn('tip_amount', F.col('tip_amount').cast('double'))
greentripdata = greentripdata.withColumn('trip_distance', F.col('trip_distance').cast('double'))
greentaxitrips_full_year = greentripdata.groupby('PULocationID', 'year').agg(
F.sum('trip_distance').alias('trip_distance'),
F.sum('total_amount').alias('total_amount'),
F.sum('tip_amount').alias('tip_amount')
)
yellowtaxitrips_full_year = yellowtripdata.groupby('PULocationID', 'year').agg(
F.sum('trip_distance').alias('trip_distance'),
F.sum('total_amount').alias('total_amount'),
F.sum('tip_amount').alias('tip_amount')
)
w = Window.partitionBy('year').orderBy(F.col('trip_distance').desc())
yellowtaxitrips_full_year = yellowtaxitrips_full_year.withColumn('rank',F.row_number().over(w))
w1 = Window.partitionBy('year').orderBy(F.col('trip_distance').desc())
greentaxitrips_full_year = greentaxitrips_full_year.withColumn('rank',F.row_number().over(w1))
print(yellowtaxitrips_full_year.filter(F.col('rank') <= 10).orderBy('year','rank').head(75))
print(greentaxitrips_full_year.filter(F.col('rank') <= 10).orderBy('year','rank').head(75))
spark.stop()
EOF
Let’s upload sample pod templates and python script to s3 bucket.
aws s3 cp nytaxi.py ${s3DemoBucket}
aws s3 cp spark_driver_nyc_taxi_template.yml ${s3DemoBucket}/pod_templates/
aws s3 cp spark_executor_nyc_taxi_template.yml ${s3DemoBucket}/pod_templates/
Let’s create a json input file for emr-container cli.
cat > request-nytaxi.json <<EOF
{
"name": "nytaxi",
"virtualClusterId": "${VIRTUAL_CLUSTER_ID}",
"executionRoleArn": "${EMR_ROLE_ARN}",
"releaseLabel": "emr-5.33.0-latest",
"jobDriver": {
"sparkSubmitJobDriver": {
"entryPoint": "${s3DemoBucket}/nytaxi.py",
"sparkSubmitParameters": "--conf spark.kubernetes.driver.podTemplateFile=${s3DemoBucket}/pod_templates/spark_driver_nyc_taxi_template.yml \
--conf spark.kubernetes.executor.podTemplateFile=${s3DemoBucket}/pod_templates/spark_executor_nyc_taxi_template.yml \
--conf spark.executor.instances=3 \
--conf spark.executor.memory=2G \
--conf spark.executor.cores=2 \
--conf spark.driver.cores=1"
}
},
"configurationOverrides": {
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.dynamicAllocation.enabled": "false",
"spark.kubernetes.executor.deleteOnTermination": "true"
}
}
],
"monitoringConfiguration": {
"cloudWatchMonitoringConfiguration": {
"logGroupName": "/emr-on-eks/eksworkshop-eksctl",
"logStreamNamePrefix": "nytaxi"
},
"s3MonitoringConfiguration": {
"logUri": "${s3DemoBucket}/"
}
}
}
}
EOF
Finally, let’s trigger the Spark job
aws emr-containers start-job-run --cli-input-json file://request-nytaxi.json
The spark job will run for around 5-7 minutes. You can watch the EKS pods using below command
watch kubectl get pods -n spark
You will be able to see the completed job in EMR console. It should look like below:

Analyzing Results of Spark Job
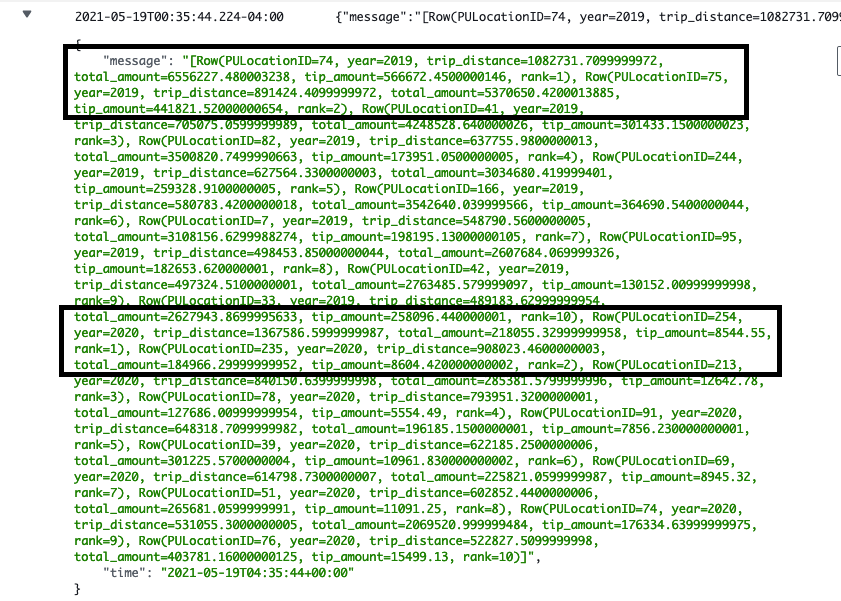
The results of the spark job are avilable in CloudWatch under log group “/emr-on-eks/eksworkshop-eksctl” in a spark driver log stream ending in “stdout”. For example the results of our spark job can be seen at “nytaxi/ftuls1q50staavpu9914lln00/jobs/00000002uc2sglcmtm4/containers/spark-797747e3709842048d8fa6d1feda3cb2/spark-00000002uc2sglcmtm4-driver/stdout”
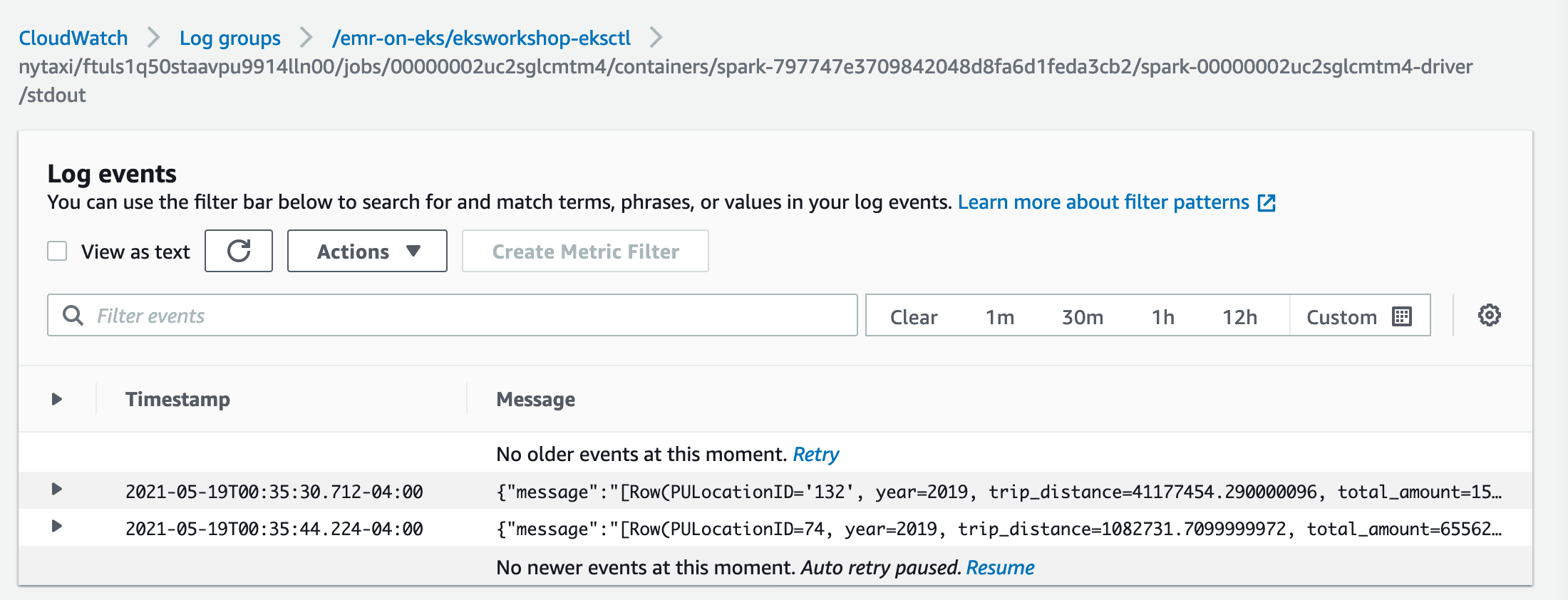
As we can see, for yellow cabs, the most famous pickup locations are “132” and “138” for both 2019 and 2020. “132” and “138” are the codes for JFK and LaGuardia airports. The code to location mapping is defined at https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page under “Taxi Zone Lookup Table”.
“132”/JFK is the busiest location for both 2019 and 2020 and we can see the significant drop in traffic due to covid-19. For 2019, the cumulative distance travelled by all yellow cabs from JFK as a pickup location was 41.1 million miles. The number dropped to 9 million miles for 2020.
Similarly, the total distance travelled for second most busiest pick up location (138/LaGuardia) dropped from 19.8 million miles to 3.6 million miles.
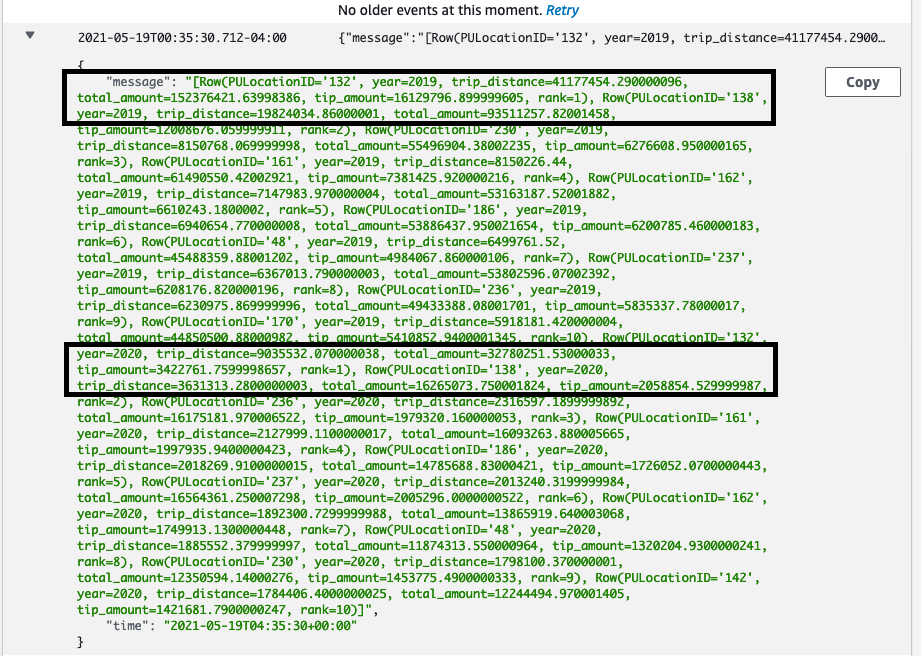
For Green Cabs, top two locations in 2019 were “74” and “75” in 2019. This changed to “254” and “235” in 2020.